A recursive function is a function which calls itself. The program uses a particular function repeatedly to accomplish a specific task. But before we dive deep into recursive functions, it is important to understand the call-stack properly first.
Call-stack:
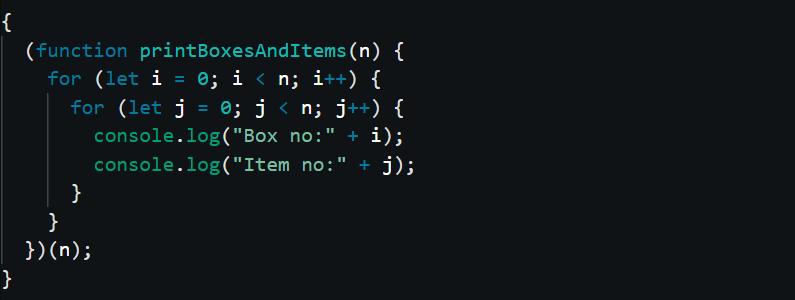
Consider,
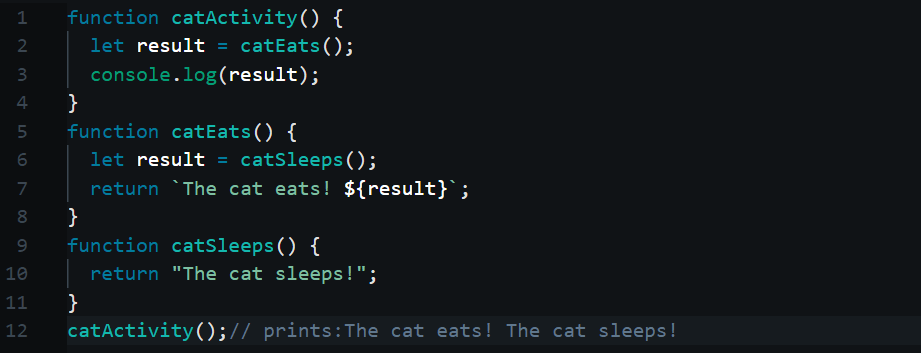
The above code is kind of like recursion. So what is going on here? The code calls the function catActivity(). catActivity() in turn calls catEats() and catEats() in turn calls catSleeps(). Then catSleeps() returns a string result. catEat() appends the result, from catSleeps(), to the another string and returns it to catActivity(). catActivity() prints the string result eventually. But something is going on in the middle. When a function is called, the function call is pushed into something called a call-stack. What is a stack?
According to Wikipedia:
“In computer science, a stack is an abstract data type that serves as a collection of elements, with two principal operations:
- push, which adds an element to the collection, and
- pop, which removes the most recently added element that was not yet removed.
The order in which elements come off a stack gives rise to its alternative name, LIFO (last in, first out).”
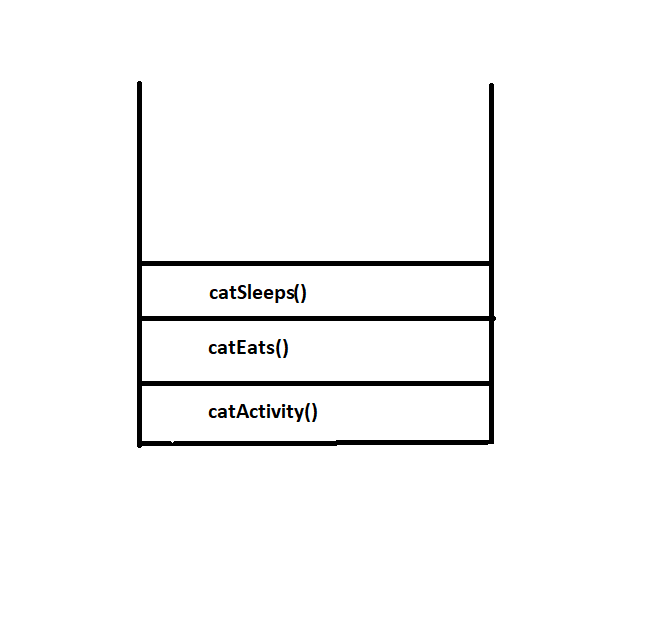
For the sake of clarity, a stack is like your laundry bucket. When you put all your dirty clothes into the bucket, the first cloth you can get out of that bucket will obviously be the last cloth you put in (unless you want to stick your hand into your dirty laundry and grab something at the bottom. Let’s not even go there). Now that’s how a stack works. The first element that goes into a stack will be the last to come out. It is a vital data-structure methodology. In this case, we are using a stack to keep track of all the method calls. JavaScript is not the only language that uses a call stack. Most languages use this methodology. So in the above code, the first function call to get into the stack, would be catActivity() and the last to get into the stack would be catSleeps(). So after catSleeps() returns a string value, it will be the first to be popped/ removed from the stack. It was the last to be added to the stack.
A function that returns void(or nothing) will be removed from the stack after the execution of its last statement and a function that returns a value will be removed from the stack after the execution of the return statement.
So after catSleeps(), catEats() will return its string result and be removed from the stack. The last method call, catActivity() will be removed from the stack after it console.logs the string result from catEats(). Hence the first the method-call that went into the stack was the last to come out of the stack. So don’t forget. Your code, will always use a stack to keep track of its function/method calls. Recursion heavily relies on this concept. We will now dive into the main topic, Recursion.
Recursion:
Consider,
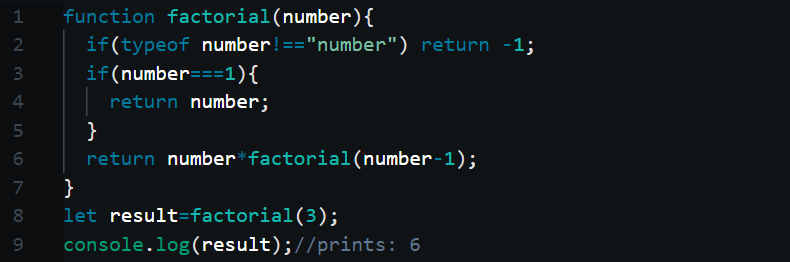
The above code calculates the factorial of 3. For your information, this code cannot calculate the factorial of very large numbers. I am just using it’s because its easy to understand. If you can’t understand the term ‘factorial’, please google it. The factorial of 3 is equal to 3*2*1. The result of the product is 6. Now how does our code calculate this? We will see. The code starts the execution at line 8(obviously!). The code will run in the order of the explanation steps below.
Code Explanation:
Line 8: calling the factorial function with the argument 3.
Line 1: the code enters the function with the argument 3 i.e.,inside the function scope, number is now equal to 3
Line 2: the line checks if the value of number is actually a number.
Line 3: the line checks if the argument value is equal to 1 i.e., it checks if it is the last number of the product. The check fails.
Line 6: this is where the magic happens. The function calls itself with a different argument value, 2(because number-1=2, i.e.,3-1=1). Now the call stack ,along with factorial(3), has another function call, factorial(2).The return statement of factorial(3) is now waiting for factorial(2) to return a value, in the stack.
Lines 1 to 5 are once again executed. The code enters the function with the argument 2 i.e., inside this function scope, number is equal to 2.
Line 6: the function calls itself with a different argument value again, 1(because number-1=1. i.e., 2-1=1). Now the call stack ,along with factorial(3) and factorial(2), has another function call,factorial(1).The return statement of factorial(2) is now waiting for factorial(1) to return a value, in the stack.
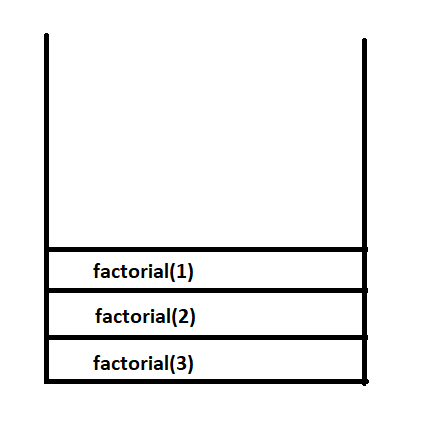
Line 1 to 2 are once again executed. The code enters the function with the argument 1 i.e., inside this function scope, number is equal to 1.
Line 3: as number is now equal to 1, the code enters the if statement.
Line 4: The code returns number, which, according to this scope, is 1. The function call, factorial(1) reaches completion and is removed/popped from the stack.
Line 6: The function call, factorial (2), which was waiting for factorial(1) to return a value , is now ready to return a value. factorial (2) gets 1 from factorial(1), i.e., the value factorial(1) returned. factorial (2) returns 2 after the multiplication of 2 and 1(2 is the value of number in this scope, and 1 is the value coming from the function call, factorial(1) ). factorial (2) is now popped from the stack.
Line 6: The function call, factorial(3), which was waiting for factorial(2) to return a value , is now ready to return a value. factorial(3) gets 2 from factorial(2) i.e., the value factorial(2) returned. factorial(3) returns 6 after the multiplication of,3 and 2 (3 is the value of number in this scope, and 2 is the returned value coming from the function call factorial(2) ).factorial(3) is the last function call to be popped from the stack and it was the first function call to enter the call stack.
Line 8: The variable result stores the value from the function call (factorial(3)).
Line 9: prints 6 the result.
In short, the factorial function calls itself using different arguments, until it satisfies the condition, number===1. After that point, it returns the values produced by the function calls. The returned values from each function call are multiplied with each other and the code eventually returns the factorial of 3.
So a recursive function does two things to accomplish a task; it calls itself repeatedly to satisfy a specific condition and after it satisfies that condition, it returns the result of every function call in the stack. This chain reaction eventually produces a valid result. There is also a limit to how much a stack can hold. That’s about it. I hope this was understandable. I’ll be back. Thank you for reading!



{kind=link}