The merge sort is a very popular sorting algorithm. JavaScript comes with its own sorting function (sort()). However the sorting algorithms used by the various browsers are different from each other. So when you use sort() to sort an array with Mozilla firefox, firefox will automatically use the merge sort algorithm. Likewise, chrome uses a different algorithm when you use sort(). With that said let’s dive into merge sort!
Algorithm:
- With recursion,split the array to be sorted into two equal parts.
- Split the two splitted-up arrays repeatedly, until the program returns an array with a single/no value.
- With that done, sort and merge the splitted-up arrays and return the sorted array to the previous stack. The sorting should be done by comparing one splitted-up array with another. Repeat this step until the program merges and sorts all the splitted-up arrays. Eventually after all the call-stacks are removed, the program will have the fully sorted array.
- Return the sorted array.
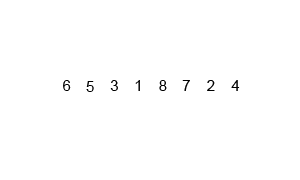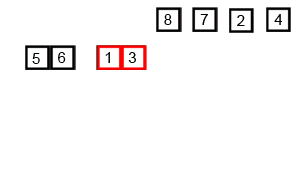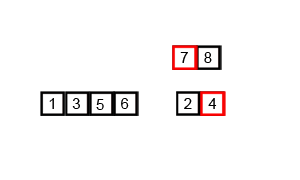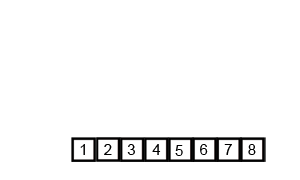
Code:
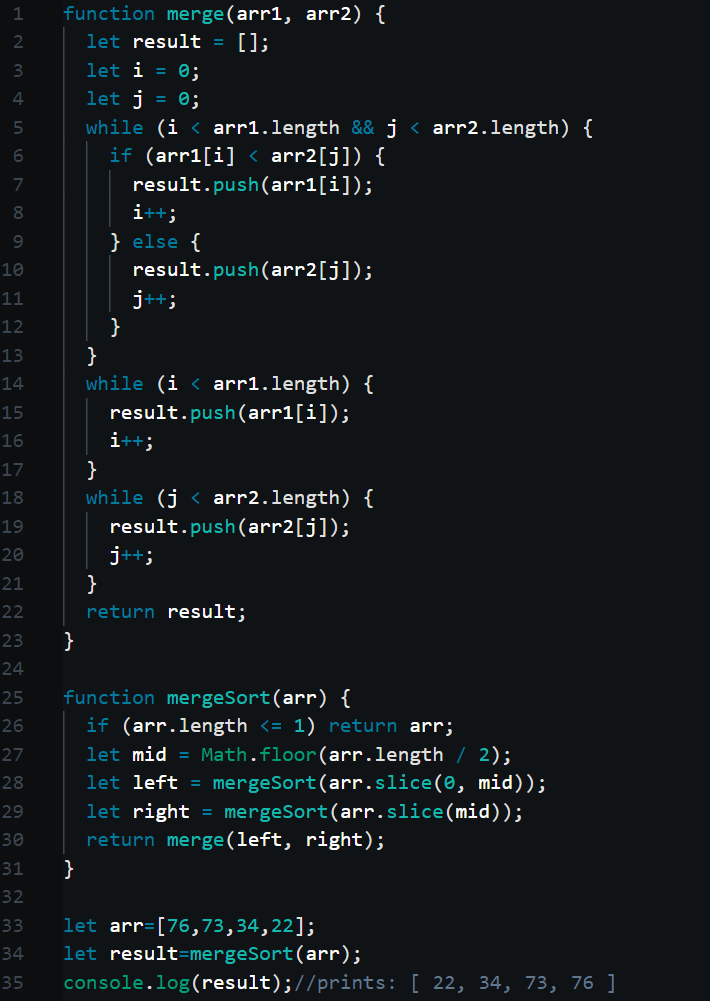
Code explanation:
I know. The algorithm didn’t make a lot of sense. We have two functions. One function ,mergeSort(), splits the array into many parts using recursion. The other ,merge(), sorts the splitted-up arrays and merges them together. So let’s try to sort the small array ,[76,73,34,22] with our code.
Step 1:
[76,73,34,22]
- Line number 34: The mergeSort function is called with the array argument [76,73,34,22].
- Line number 26: checks the length of the array. If it is less than or equal to one, the array is returned back. This is an important step. You will see why.
- Line number 27: finds the array’s middle most index. The middle index of the array is 2.
- Line number 28: with the array’s middle most index, we slice the array (from the 0th index to the middle index.). The slice gives us [76,73] and with this new array argument we call the mergeSort() function again. This will push another mergeSort() function call into the call stack. The function call mergeSort([76,73,34,22]) waits for the second function call mergeSort([76,73]) to return a value. The code will resume execution after that.
Step 2:
[76,73]
- The array argument([76,73]) enters the mergeSort() function.
- Lines 26-27: these lines are executed again. The middle index of this array argument is 2 The code continues to line number 28.
- Line number 28: with the array’s new middle most index, we slice the array (from the 0th index to the middle index.). The slice gives us [76] and with this new array argument we call the mergeSort() function again. This will push another mergeSort() function call into the call stack. This function call mergeSort([76,73]) waits for the function call mergeSort([76]) to return a value. The code will resume execution after that.
Step 3:
[76]
- The array argument([76]) enters the mergeSort() function.
- Line number 26: checks the length of the array. If it is less than or equal to one, the array will be returned back. The length of the array argument([76]) is one and hence the code will return the value. This function call mergeSort([76]) is popped from the array.
Step 4:
[76,73]
- Line number 28: The code will continue the execution of the previous function call mergeSort([76,76]). The value [76] returned by the function call mergeSort([76]) is stored inside the variable left. For the sake of clarity the value of the array argument inside this scope is still [76,73] and the middle index of the array argument is 2. The slice() function creates a new array without changing the original array.
- Line number 29: with the array’s middle most index, we slice the array (from the middle index to the last index. The middle index is 2.) again. The slice gives us [73] and with this new array argument we call the mergeSort() function again. This will push another mergeSort() function call into the call stack. The function call mergeSort([76,73]) waits again for the function call mergeSort([73]) to return a value. The code will resume execution after that.
Step 5:
[73]
- The array argument([73]) enters the mergeSort() function.
- Line number 26: checks the length of the array. If it is less than or equal to one, the array will be returned back. The length of the array argument([73]) is one and hence the code will return the value. This function call mergeSort([73]) is popped from the array.
Step 6:
[76,73]
- Line number 29:The code will continue the execution of the previous function call mergeSort([76,73]). The value [73] returned by the function call mergeSort([73]) is stored inside the variable right.
- Line number 30: the code has both the values(left and right) necessary to call the merge() function. The merge() function is called with the variables left([76]) and right([73])
Step 7:
[76],[73]
- The array arguments, [76] and [73] enter the merge() function.
- Lines 2-4: three variables namely result ,i and j are declared; result is an array variable that will be used to store the eventual result(the merge-sorted array). The two arrays will be traversed. i keeps track of the indexes of the first array and j keeps track of the indexes of the second array.
- Lines 5-13: the while loop runs until one of the arrays or both the arrays are traversed completely. The value at a particular index(i and j represents indexes.initially i and j are zero) of the first array(in this case [76]) is compared with the value at a particular index of the second array (in this case [73]) and if the value from the first array(arr1[i]) is smaller than the value from the second(arr2[j]), the value of the first array is pushed into the result array and the i is incremented by one. Else the value from the second array is pushed into the result array ,for being obviously smaller than the array from the first array, and the variable j isincremented by one. In this scenario, the value 73 is pushed into the result array first, followed by 76.
- Lines 14-21: these while loops are used to push the rest of the values of the two array arguments. If one of the two array arguments(arr1[i]/arr2[j]) is traversed completely(i.e.,once the code traverses all the indexes within length) before the other array, the code will push the rest of the values of the array which still has indexes that need to traversed, into the result array.
- Line number 22: This process sorts (by comparing the values from the two arguments) and merges the two array arguments. The result array or the sorted array) array [73,76] is returned.
Step 8:
[34,22]
- Line number 28: The function call mergeSort([76,73]) will be popped from the call stack . The array value [73,76] ,from the function call mergeSort([76,73]), is returned to the function call mergeSort([76,73,34,22]) and store inside left.
- The recursion process is repeated and the function call mergeSort(34,22) eventually returns the sorted result [22,34]. This result array ,[22,34], is stored inside right.
- Line number 30: the code has both the values(left and right) necessary to call the merge() function. The merge() function is called with the variables left([73,76]) and right([22,34]) and the merge() function will return the result [22,34,73,76], the final solution. The eventual result ,[22,34,73,76], is returned by the function call mergeSort([76,73,34,22]) and it is popped from the call stack.
Step 9:
[22, 34,73,76]
- Line number 34: The sorted array is stored inside result
- Line number 35: The result is printed.
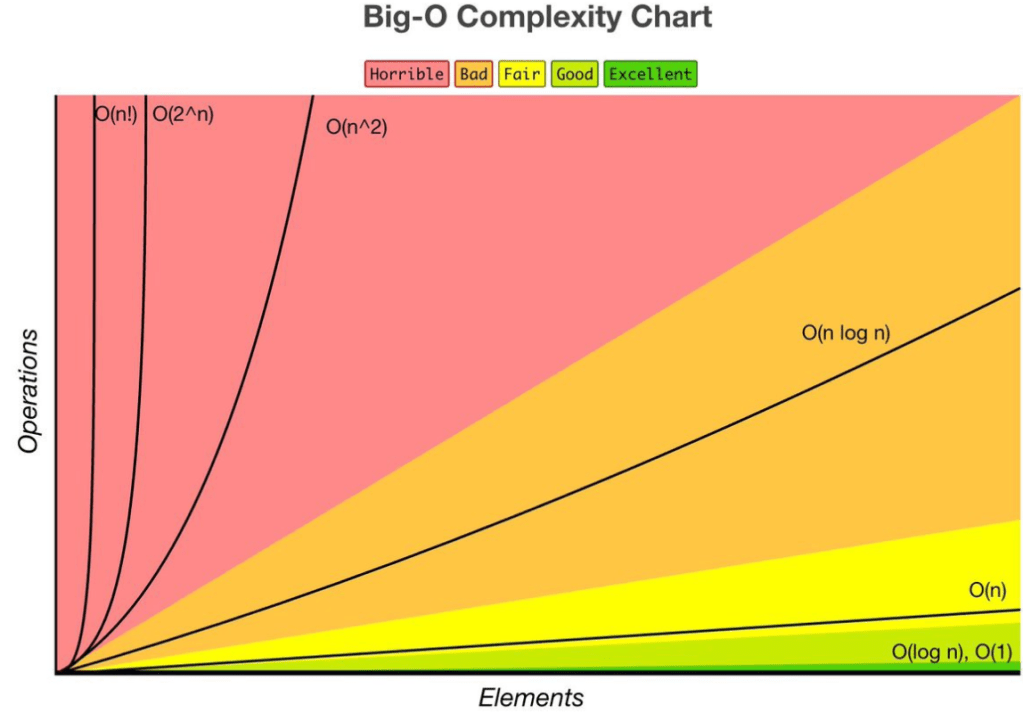
Big “O”:
The Big “O” of the merge sort algortithm is O(nlog), which is very good for a sorting algorithm. We have two parts to consider here; ‘n’ and ‘logn’. Firstly ,according to the algorithm, the code splits the array into many halves, and stops when it can’t go any further. This splitting-up process equals to O(logn). Now we have our first part. Secondly, according to the algorithm, the code merges and sorts the splitted-up arrays. It sorts them by comparing the values of the splitted-up arrays. This process of merging and sorting equals to O(n), because the comparisons made here depends on the number of values the array has. When we multiply these two, we get O(nlogn). The space complexity of the merge sort algorithm is O(n), as you have to store the splitted-up arrays; and that depends on the length of your array.
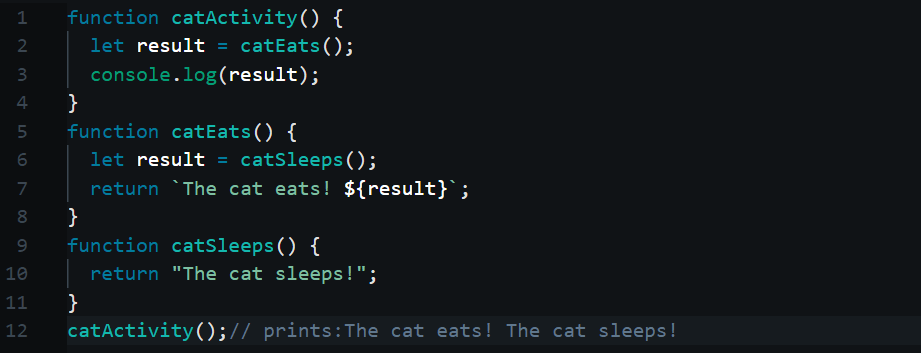
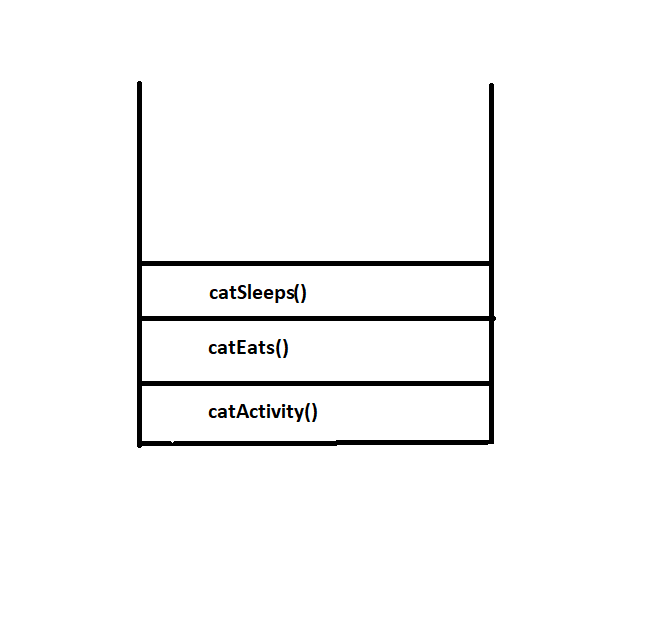
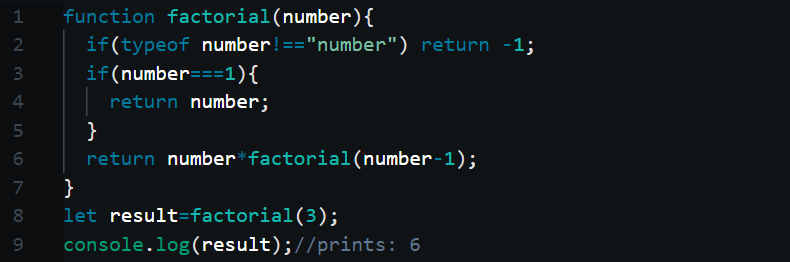



{kind=link}